Mails mit n8n für Paperless NGX konvertieren
Paperless NGX kann von Hause aus schon recht gut mit Mails umgehen. Ich kann wählen, ob ich die Nachricht als eml verarbeiten möchte, ob ich nur die Attachments verarbeiten möchte oder sowohl Nachricht als auch Attachments. Das ist schon ganz nett. Nun möchte ich Mails aber immer komplett und als eine Einheit, also Nachricht und Attachments als ein Dokument ablegen. Dafür habe ich mir einen n8n-Workflow ausgedacht, den ich mit Unterstützung der KI Claude realisiert habe. Mails, die als neu in einem Unterordner "archivieren" eingehen, sollen vom Workflow verarbeitet werden. Die Nachricht wird nach PDF konvertiert, wobei am Ende der Nachricht die Attachments aufgezählt werden und anschließend werden die Attachments an das PDF gehängt. Dieses gesammelte Werk wird dann nach Paperless NGX übertragen und im Mailpostfach vom Unterordner "archivieren" in den Unterordner "archiviert" verschoben.
Vorbereitungen bzw. Voraussetzungen
Ich benötige für mein Vorhaben natürlich einen n8n-Server. Wie ich den mit Docker aufgesetzt habe, habe ich hier beschrieben. Hier ist aber eine kleine Ergänzung wichtig: In der Datei docker-compose.yml muss im Abschnitt Environment folgende Zeile ergänzt werden:
environment:
...
- NODE_FUNCTION_ALLOW_BUILTIN=buffer,http
Dann muss ich in Paperless NGX einen neuen Benutzer anlegen und für diesen ein API-Token generieren. Man kann dazu auch einfach seinen eigenen Benutzeraccount verwenden, aber mir erschien es sauberer, dafür einen Diensteaccount, den ich n8n genannt habe, anzulegen. Nachdem ich den Benutzer angelegt habe, habe ich mich an Paperless NGX mit diesem Account angemeldet und unter "Mein Profil" ein API-Authentifizierungstoken generiert und kopiert.
Auf der Web-GUI von n8n habe ich dann unter Credentials neue Credentials für meinen Workflow generiert. Zunächst habe ich einen neuen Header auth account angelegt. Unter "Name" habe ich "Authorization" eingetragen. Unter "Value" das soeben generierte Token und unter "Allowed HTTP Request Domains" stand bereits "All". Das habe ich so gelassen. Nun muss n8n auch noch Mails abrufen können und benötigt dazu einen SMTP Account. Also habe ich dafür unter Credentials die erforderlichen Daten eingetragen. Das ist hier selbst erklärend. Das sind die selben Daten, die man auch in einem Mailclient für einen neuen Mail-Account eintragen würde.
Der Workflow
Grafisch stellt sich der Workflow wie folgt dar:
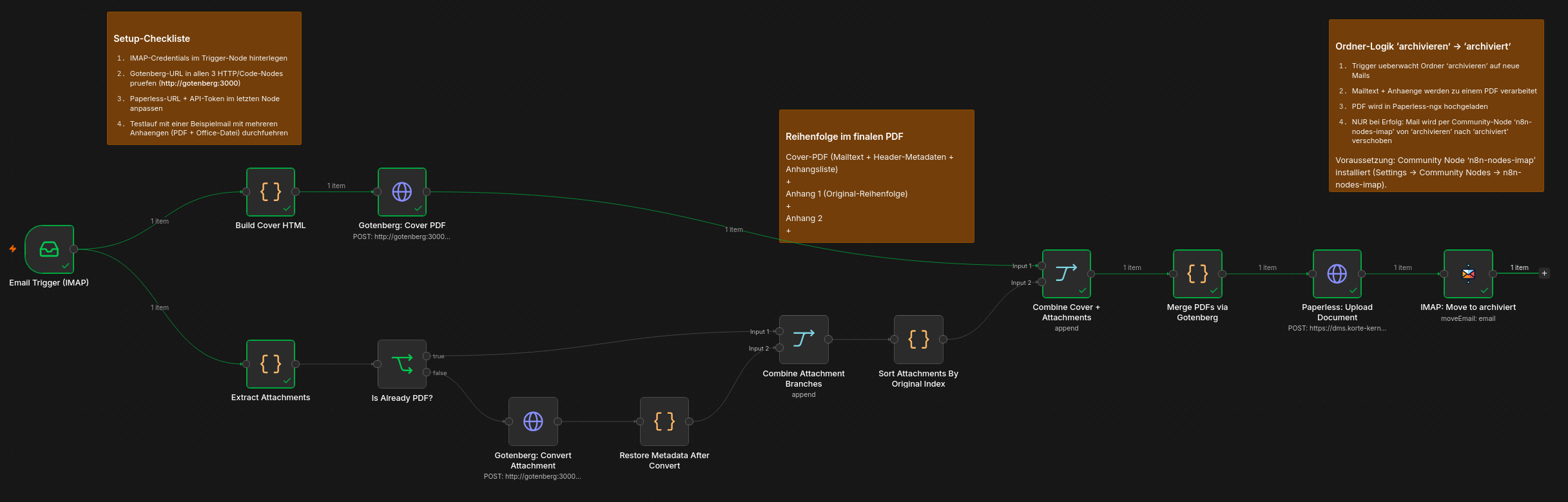
Die Triggernode
Die erste Node ist eine Triggernode, die den Workflow bei neu eingegangenen Mails immer startet. Unter Credentials wähle ich hier natürlich den soeben erstellten SMTP-Account aus. Mailboxname ist in meinem Fall "INBOX/archivieren", also ein Ordner "archivieren" unterhalb des Posteingangs. Diese erste Node hat zwei Ausgänge, das heißt, hier teilt sich der Workflow in zwei Pfade auf, die unkonditional ausgeführt werden.
Node Build Cover HTML
In dem einen Strang wird zunächst die Mail in einer Code Node mit JavaScript so formatiert, wie ich sie haben möchte. Eigentlich ist n8n ja eine "Low-Code/No-Code-Plattform" aber was solls. Der Code sieht so aus:
const inputItem = $input.first();
const mail = inputItem.json;
// Original-Dateinamen der Anhänge direkt aus den Binärdaten dieses Items lesen
const attachmentNames = [];
for (const key of Object.keys(inputItem.binary || {})) {
if (key.toLowerCase().startsWith('attachment')) {
attachmentNames.push(inputItem.binary[key].fileName || key);
}
}
function esc(str) {
return String(str ?? '')
.replace(/&/g, '&')
.replace(//g, '>');
}
// HINWEIS: Feldnamen je nach n8n-/IMAP-Node-Version ggf. anpassen!
// Im n8n-Editor einfach eine Testmail durchlaufen lassen und die
// tatsächliche JSON-Struktur des Trigger-Outputs prüfen.
const fromName = mail.from?.value?.[0]?.name || mail.fromName || '';
const fromAddress = mail.from?.value?.[0]?.address || mail.fromAddress || mail.from || '';
const toAddress = (mail.to?.value || []).map(v => v.address).join(', ') || mail.to || '';
const dateStr = mail.date || '';
const subject = mail.subject || '(kein Betreff)';
const bodyHtml = mail.html || mail.textHtml || `${esc(mail.text || '')}`;
const attachmentListHtml = attachmentNames.length
? `<h3>Anhänge</h3><ul>${attachmentNames.map(n => `${esc(n)} `).join('')}`
: '';
const html = `<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<style>
body { font-family: Arial, Helvetica, sans-serif; font-size: 12px; color: #222; margin: 30px; }
table.meta { width: 100%; border-collapse: collapse; margin-bottom: 16px; }
table.meta td { padding: 3px 8px; vertical-align: top; }
table.meta td.label { font-weight: bold; width: 150px; color: #555; }
.subject { font-size: 16px; font-weight: bold; margin: 10px 0 18px; border-bottom: 2px solid #333; padding-bottom: 6px; }
.body-content { margin-top: 16px; line-height: 1.45; word-wrap: break-word; }
.attachments { margin-top: 24px; border-top: 1px solid #ccc; padding-top: 10px; }
.attachments ul { margin-top: 6px; }
</style>
</head>
<body>
<table class="meta">
<tr><td class="label">Von:</td><td>${esc(fromName)} <${esc(fromAddress)}></td></tr>
<tr><td class="label">Datum:</td><td>${esc(dateStr)}</td></tr>
<tr><td class="label">An (Postfach):</td><td>${esc(toAddress)}</td></tr>
</table>
<div class="subject">${esc(subject)}</div>
<div class="body-content">${bodyHtml}</div>
<div class="attachments">${attachmentListHtml}</div>
</body>
</html>`;
return [{
json: {
subject,
mailDate: dateStr
},
binary: {
index: {
data: Buffer.from(html, 'utf-8').toString('base64'),
fileName: 'index.html',
mimeType: 'text/html'
}
}
}];
Node Gotenberg: Cover PDF
Die nächste Node in diesem Pfad ist ein HTTP-Request. Als Methode wird "POST" ausgewählt und als url "http://gotenberg:3000/forms/chromium/convert/html" eingegeben. Das funktioniert natürlich nur, wenn der n8n-Container Gotenberg über den Namen im selben Netzwerk ansprechen kann (s. hierzu: Projekte/Dockerkonsolidierung). Andernfalls muss eine IP-Adresse oder ein FQDN anstelle von "gotenberg" eingetragen werden. Dann muss der Schalter "Send Body" aktiviert werden. Jetzt habe ich noch dreimal Body-Content-Types ergänzen (das kleine Plus-Symbol neben "Body"). Der erste ist vom Typ "formBinaryData", "name" ist "files und "InputDataFieldName" ist "index". Das definiert, in welchem Format die Daten an Gotenberg übermittelt werden. Der zweite und dritte sind vom Typ "Form Data". Mit "paperWidth" Value "8.27" wird die Papierbreite mit 8,27 Zoll und mit "paperHeight" Value "11.69" die Höhe auf 11,69 Zoll festgelegt. Das entspricht DIN A 4. Ohne diese beiden Parameter würde Gotenberg die Nachricht als US-Letter formatieren. Unter Options gebe ich noch das Response-Format "File" und das Ausgabefeld "data" vor. Das Ergebnis dieser Node ist eine PDF-Datei, die die von mir gewünschten Headerdaten, den Betreff, den Nachrichtentext und eine Aufzählung der Attachments enthält, wenn es Attachments gibt.
Node Extract Attachments
Im zweiten Pfad wird in einer Code-Node mit folgendem JavaScript-Code
const inputItem = $input.first();
const binaryKeys = Object.keys(inputItem.binary || {})
.filter(k => k.toLowerCase().startsWith('attachment'));
if (binaryKeys.length === 0) {
// Keine Anhänge vorhanden - dieser Zweig liefert dann einfach keine Items,
// der Merge-Schritt weiter unten bekommt nur das Cover-PDF.
return [];
}
return binaryKeys.map((key, idx) => {
const bin = inputItem.binary[key];
return {
json: {
originalIndex: idx,
originalName: bin.fileName || `attachment_${idx}`,
mimeType: bin.mimeType || 'application/octet-stream'
},
binary: {
data: bin
}
};
});
Node Gotenberg: Convert Attachment
Wenn nicht, wird es in der nächsten Node, die wieder einen HTTP-Request darstellt, mittels Gotenberg nach PDF konvertiert. Die Parameter sind wieder ähnlich wie in der vorherigen HTTP-Request-Node an Gotenberg. Methode ist "Post", "URL ist "http://gotenberg:3000/forms/libreoffice/convert", Schalter "Send Body" gesetzt, Body Content Type ist "Form-Data". Als Body Field Type ist nur "files" vom Typ "n8n Binary File" mit Name "file" und Input Data Field Name "data" einzutragen. Unter Options/Response ist noch das Response Format File und das Ausgabefeld data zu definieren.
Node Restore Metadata After Convert
Nach der Gotenberg-Konvertierung von Office-Dateien gehen Original-Metadaten im JSON-Teil des Items oft verloren, weil der HTTP-Request-Node den Binär-Response als neues Item zurückgibt. Darum holen wir uns die Metadaten aus der Node "Extract Attachments" per JavaScript zurück. Dafür definiere ich eine Script-Node mit folgendem Code:
const converted = $input.first();
const original = $('Extract Attachments1').item;
return [{
json: {
originalIndex: original.json.originalIndex,
originalName: original.json.originalName,
mimeType: 'application/pdf'
},
binary: {
data: converted.binary.data
}
}];
Node Sort Attachments By Original Index
Natürlich möchte ich, dass die Nachricht und die Attachments in der korrekten Reihenfolge verarbeitet werden. Darum füge noch eine Code-Node mit folgendem JavaScript ein:
// Alle konvertierten + bereits-PDF-Anhänge wieder in die ursprüngliche
// Anhang-Reihenfolge der E-Mail sortieren.
const all = $input.all();
return all
.filter(i => i.json && i.json.originalIndex !== undefined)
.sort((a, b) => a.json.originalIndex - b.json.originalIndex);
Weiterverarbeitung und Merge zu einem PDF mit Gotenberg
Zunächst füge ich eine einfache Merge-Node ein und verbinde sie mit den beiden Strängen meines bisherigen Workflows. Hier fließen nun also Nachricht und Attachments zusammen. In der Node "Merge PDFs via Gotenberg" werden die Nachricht und die Attachments per HTTP-Request an Gotenberg übergeben, mit der freundlichen Bitte, daraus ein Gesamt-PDF zu machen. Hierbei mussten Claude und ich gemeinsam ein wenig probieren ;-) Dabei haben wir beide folgendes gelernt:
- Binärdaten IMMER über getBinaryDataBuffer() lesen, NICHT über item.binary.data.data direkt.
- this.helpers.httpRequest() (axios) und globales fetch() haben sich beide als unzuverlässig herausgestellt beim Senden von multipart/form-data mit mehreren dynamischen Dateien (415 / "no form file found"). fetch() war zudem im Sandbox gar nicht verfügbar.
- Deshalb hier: rohes Node-Core-Modul 'http' nutzen - keine automatische Content-Type-Erkennung, kein "Mitdenken" einer Bibliothek, volle Kontrolle über die Bytes auf der Leitung.
const http = require('http');
const items = $input.all();
function safeBaseName(name) {
return String(name || 'datei').replace(/\.[^/.]+$/, '').replace(/[^a-zA-Z0-9_\-]/g, '_');
}
function buildMultipart(parts) {
const boundary = '----n8nGotenberg' + Date.now();
const chunks = [];
for (const part of parts) {
chunks.push(Buffer.from(`--${boundary}\r\n`));
chunks.push(Buffer.from(`Content-Disposition: form-data; name="files"; filename="${part.filename}"\r\n`));
chunks.push(Buffer.from(`Content-Type: ${part.contentType}\r\n\r\n`));
chunks.push(part.data);
chunks.push(Buffer.from('\r\n'));
}
chunks.push(Buffer.from(`--${boundary}--\r\n`));
return { body: Buffer.concat(chunks), boundary };
}
function postMultipart(host, port, path, body, boundary) {
return new Promise((resolve, reject) => {
const req = http.request(
{
host,
port,
path,
method: 'POST',
headers: {
'Content-Type': `multipart/form-data; boundary=${boundary}`,
'Content-Length': body.length
}
},
(res) => {
const responseChunks = [];
res.on('data', (c) => responseChunks.push(c));
res.on('end', () => {
const responseBuffer = Buffer.concat(responseChunks);
if (res.statusCode < 200 || res.statusCode >= 300) {
reject(new Error(`HTTP ${res.statusCode}: ${responseBuffer.toString('utf-8')}`));
} else {
resolve(responseBuffer);
}
});
}
);
req.on('error', reject);
req.write(body);
req.end();
});
}
const parts = [];
for (let idx = 0; idx < items.length; idx++) {
const item = items[idx];
const buffer = await this.helpers.getBinaryDataBuffer(idx, 'data');
if (!buffer || buffer.length === 0) {
throw new Error(`Leeres Binary bei Item ${idx} (originalName: ${item.json.originalName || 'Cover'}) - Datei wurde nicht korrekt durchgereicht.`);
}
const filename = idx === 0
? '0_mailtext.pdf'
: `${idx}_${safeBaseName(item.json.originalName)}.pdf`;
parts.push({ filename, contentType: 'application/pdf', data: buffer });
}
const { body, boundary } = buildMultipart(parts);
let mergedBuffer;
try {
// Host/Port ggf. anpassen, falls Gotenberg nicht unter 'gotenberg:3000' im Docker-Netz läuft
mergedBuffer = await postMultipart('gotenberg', 3000, '/forms/pdfengines/merge', body, boundary);
} catch (error) {
throw new Error(`Gotenberg-Merge fehlgeschlagen: ${error.message}`);
}
return [{
json: {
mergedFileCount: items.length,
subject: $('Build Cover HTML1').first().json.subject,
mailDate: $('Build Cover HTML1').first().json.mailDate
},
binary: {
data: {
data: mergedBuffer.toString('base64'),
fileName: 'merged.pdf',
mimeType: 'application/pdf'
}
}
}];
Node Paperless: Upload Document
Die nächste Node ist wieder ein HTTP-Request. Die Methode ist wieder "Post". Interessant ist hier der URL. Er sieht in meiner Umgebung wie folgt aus: "https://dms.korte-kernke.koeln/api/documents/post_document/". Wobei der FQDN korte-kernke.koeln nur in meiner Umgebung aufgelöst korrekt wird (DNS-Split s. dazu: dnsmasq und Caddy). Unter "Authentication" wähle ich "Generic Credential Type" und unter "Generic Auth Type" "Haeder Auth account" aus, setze wieder den Schalter "Send Headers" und wähle "Using Fields Below" aus. Name ist "Authorization" (natürlich ohne Anführungszeichen) und Value das Token, das ich vorher unter Paperless-NGX erstellt habe mit der Zeichenkette "Token " davor.
Dann switche ich den Schalter "Send Body" ein füge ein Body Field mit Type "n8n Binary File", Name "document" und Input Data Field Name "data", ein Body Field vom Typ "Form Data" mit Namen "title" und dem Value "{{ $('Build Cover HTML1').first().json.subject }}" sowie ein Body Field vom Typ "Fomr Data" mit Namen "created" und dem Value "{{ $('Build Cover HTML1').first().json.mailDate }}" ein. Unter Response wähle ich das Response Format "Text" und das Ausgabefeld "data" aus.
Verschieben der Mail von "archivieren" nach "archiviert"
Nun brauche ich eine Community-Node namens "n8n-nodes-imap". Dazu muss ich diese Node auf der Web-GUI von n8n unter Settings/Community Nodes/Install hinzufügen. Dann wähle ich diese Node aus und wähle unter Credentials meinen IMAP Account aus. Ressource ist "Email", Operation "Move". Source Mailbox ist "From list: INBOX/archivieren". Die Email-UID wird über die folgende Expression definiert: "{{ $('Email Trigger (IMAP)').item.json.attributes.uid }}". Destination Mailbox ist dann natürlich "From List: INBOX/archiviert".
Ergebnis
Nachdem ich den Workflow ein paar mal mit "Execute Workflow" getestet und für gut befunden habe, habe ich ihn mit "Publish" aktiviert. Wenn ich eine neue Mail in den Ordner "archivieren" verschiebe, rennt der Workflow los, verarbeitet sie, stellt sie bei Paperless NGX ein und verschiebt sie innerhalb meines Posteingangs von "archivieren" zu "archiviert". Die Formatierung der Nachrichtenheader könnte ich vielleicht noch optimieren oder z.B. die archivierten Mails im Ordner "archiviert" als gelesen markieren. Über die Header denke ich noch nach. Dass die Mails ungelesen verschoben werden, finde ich aber eigentlich ganz gut, weil ich dann sofort sehe, dass sie verarbeitet wurden. Wenn ich mehrere Mails auf einmal in den Ordner "archivieren" verschiebe, dann werden sie nicht zuverlässig alle verarbeitet. Hier könnte ich noch an dem Trigger feilen. Da das aber eigentlich so gut wie nie vorkommt, bzw. ich das eben vermeiden kann, hat das keine Priorität.
Ansonsten bin ich sehr zufrieden mit der Lösung. Die Mails werden sauber formatiert und zu PDF konvertiert und auch die Attachments angefügt. Dabei werden Office-Dokumente, Bilddateien und natürlich PDFs verarbeitet.
Der komplette Workflow im JSON-Format
Per Copy&Paste kann man wunderbar über die Web-GUI von n8n JSON-Dateien aus der Zwischenablage einfügen, aus einzelnen Knoten oder ganzen Workflows JSON-Ausgaben erzeugen. Der hier beschriebene Workflow sieht als JSON wie folgt aus:
{
"nodes": [
{
"parameters": {
"mailbox": "INBOX/archivieren",
"postProcessAction": "nothing",
"format": "resolved",
"options": {}
},
"id": "8582e385-393b-407a-8d76-711fea8cdc5d",
"name": "Email Trigger (IMAP)",
"type": "n8n-nodes-base.emailReadImap",
"typeVersion": 2,
"position": [
-144,
1856
],
"credentials": {
"imap": {
"id": "EGxUvcSZ2FzttDYh",
"name": "IMAP account"
}
},
"notes": "Mailbox auf den Ordner 'archivieren' gestellt. postProcessAction='nothing' laesst die Mail zunaechst ungelesen/unverschoben - das eigentliche 'Verschieben nach archiviert' passiert erst am Ende des Workflows, NACHDEM der Paperless-Upload erfolgreich war. Praefereierter Wert fuer postProcessAction ggf. in der UI pruefen (None/Mark as Read - interner Wert kann 'nothing' oder 'read' heissen)."
},
{
"parameters": {
"content": "## Setup-Checkliste\n1. IMAP-Credentials im Trigger-Node hinterlegen\n2. Gotenberg-URL in allen 3 HTTP/Code-Nodes pruefen (http://gotenberg:3000)\n3. Paperless-URL + API-Token im letzten Node anpassen\n4. Testlauf mit einer Beispielmail mit mehreren Anhaengen (PDF + Office-Datei) durchfuehren\n5. Feldnamen im 'Build Cover HTML' Node ggf. an die tatsaechliche IMAP-Trigger-Struktur anpassen",
"height": 260,
"width": 380
},
"id": "138fc0b4-9d0f-4ef5-a1ec-2d5282a377e1",
"name": "Sticky Note: Setup1",
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
16,
1440
]
},
{
"parameters": {
"content": "## Reihenfolge im finalen PDF\nCover-PDF (Mailtext + Header-Metadaten + Anhangsliste)\n+\nAnhang 1 (Original-Reihenfolge)\n+\nAnhang 2\n+\n...\n\nWird sichergestellt durch:\n- originalIndex beim Aufsplitten der Anhaenge\n- Sortierung vor dem finalen Merge\n- 'append'-Merge mit Cover als erstem Input",
"height": 260,
"width": 380
},
"id": "de13f12d-bd70-45f8-a0ac-e5696e724d04",
"name": "Sticky Note: Reihenfolge1",
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
1328,
1632
]
},
{
"parameters": {
"content": "## Ordner-Logik 'archivieren' -> 'archiviert'\n1. Trigger ueberwacht Ordner 'archivieren' auf neue Mails\n2. Mailtext + Anhaenge werden zu einem PDF verarbeitet\n3. PDF wird in Paperless-ngx hochgeladen\n4. NUR bei Erfolg: Mail wird per Community-Node 'n8n-nodes-imap' von 'archivieren' nach 'archiviert' verschoben\n\nVoraussetzung: Community Node 'n8n-nodes-imap' installiert (Settings -> Community Nodes -> n8n-nodes-imap).\nOrdnername 'archiviert' muss im Postfach bereits existieren (IMAP legt Ordner i.d.R. nicht automatisch an).",
"height": 336,
"width": 420
},
"id": "e07302c8-5bf2-4e42-a787-b307c9e957ce",
"name": "Sticky Note: Ordner-Logik1",
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
2400,
1456
]
},
{
"parameters": {
"authentication": "coreImapAccount",
"resource": "email",
"operation": "moveEmail",
"sourceMailbox": {
"__rl": true,
"value": "INBOX/archivieren",
"mode": "list",
"cachedResultName": "INBOX/archivieren"
},
"emailUid": "={{ $('Email Trigger (IMAP)').item.json.attributes.uid }}",
"destinationMailbox": {
"__rl": true,
"value": "INBOX/archiviert",
"mode": "list",
"cachedResultName": "INBOX/archiviert"
}
},
"id": "906dc0ae-af44-44e8-bc7b-266f5bc064eb",
"name": "IMAP: Move to archiviert",
"type": "n8n-nodes-imap.imap",
"typeVersion": 1,
"position": [
2624,
1904
],
"credentials": {
"imap": {
"id": "EGxUvcSZ2FzttDYh",
"name": "IMAP account"
}
},
"notes": "ACHTUNG - MANUELL PRUEFEN: Dies ist der Community-Node 'n8n-nodes-imap' (https://github.com/umanamente/n8n-nodes-imap), NICHT im n8n-Kern enthalten. Muss vorher unter Settings -> Community Nodes installiert werden (Paketname: n8n-nodes-imap). Die genauen internen Werte fuer 'resource' und 'operation' (hier als 'email'/'move' angenommen) sowie das Feld fuer die Quell-UID (hier 'emailUid', vermutlich aus dem Trigger-Output 'uid') bitte nach der Installation im n8n-Editor per Dropdown nachpruefen/korrigieren - ich kann die exakten Parameter-Keys dieses Community-Nodes nicht zu 100% garantieren. Gleiches Postfach-Credential wie beim Email Trigger (IMAP) verwenden."
},
{
"parameters": {
"jsCode": "const inputItem = $input.first();\nconst mail = inputItem.json;\n\n// Original-Dateinamen der Anhänge direkt aus den Binärdaten dieses Items lesen\nconst attachmentNames = [];\nfor (const key of Object.keys(inputItem.binary || {})) {\n if (key.toLowerCase().startsWith('attachment')) {\n attachmentNames.push(inputItem.binary[key].fileName || key);\n }\n}\n\nfunction esc(str) {\n return String(str ?? '')\n .replace(/&/g, '&')\n .replace(//g, '>');\n}\n\n// HINWEIS: Feldnamen je nach n8n-/IMAP-Node-Version ggf. anpassen!\n// Im n8n-Editor einfach eine Testmail durchlaufen lassen und die\n// tatsächliche JSON-Struktur des Trigger-Outputs prüfen.\nconst fromName = mail.from?.value?.[0]?.name || mail.fromName || '';\nconst fromAddress = mail.from?.value?.[0]?.address || mail.fromAddress || mail.from || '';\nconst toAddress = (mail.to?.value || []).map(v => v.address).join(', ') || mail.to || '';\nconst dateStr = mail.date || '';\nconst subject = mail.subject || '(kein Betreff)';\nconst bodyHtml = mail.html || mail.textHtml || `${esc(mail.text || '')}`;\n\nconst attachmentListHtml = attachmentNames.length\n ? `<h3>Anhänge</h3><ul>${attachmentNames.map(n => `${esc(n)} `).join('')}`\n : '';\n\nconst html = `<!DOCTYPE html>\n<html>\n<head>\n<meta charset=\"utf-8\">\n<style>\n body { font-family: Arial, Helvetica, sans-serif; font-size: 12px; color: #222; margin: 30px; }\n table.meta { width: 100%; border-collapse: collapse; margin-bottom: 16px; }\n table.meta td { padding: 3px 8px; vertical-align: top; }\n table.meta td.label { font-weight: bold; width: 150px; color: #555; }\n .subject { font-size: 16px; font-weight: bold; margin: 10px 0 18px; border-bottom: 2px solid #333; padding-bottom: 6px; }\n .body-content { margin-top: 16px; line-height: 1.45; word-wrap: break-word; }\n .attachments { margin-top: 24px; border-top: 1px solid #ccc; padding-top: 10px; }\n .attachments ul { margin-top: 6px; }\n</style>\n</head>\n<body>\n <table class=\"meta\">\n <tr><td class=\"label\">Von:</td><td>${esc(fromName)} <${esc(fromAddress)}></td></tr>\n <tr><td class=\"label\">Datum:</td><td>${esc(dateStr)}</td></tr>\n <tr><td class=\"label\">An (Postfach):</td><td>${esc(toAddress)}</td></tr>\n </table>\n <div class=\"subject\">${esc(subject)}</div>\n <div class=\"body-content\">${bodyHtml}</div>\n <div class=\"attachments\">${attachmentListHtml}</div>\n</body>\n</html>`;\n\nreturn [{\n json: {\n subject,\n mailDate: dateStr\n },\n binary: {\n index: {\n data: Buffer.from(html, 'utf-8').toString('base64'),\n fileName: 'index.html',\n mimeType: 'text/html'\n }\n }\n}];"
},
"id": "8b41da30-81f4-4ade-bfd4-1da1e25db9b8",
"name": "Build Cover HTML",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
288,
1744
]
},
{
"parameters": {
"method": "POST",
"url": "http://gotenberg:3000/forms/chromium/convert/html",
"sendBody": true,
"contentType": "multipart-form-data",
"bodyParameters": {
"parameters": [
{
"parameterType": "formBinaryData",
"name": "files",
"inputDataFieldName": "index"
},
{
"name": "paperWidth",
"value": "8.27"
},
{
"name": "paperHeight",
"value": "11.69"
}
]
},
"options": {
"response": {
"response": {
"responseFormat": "file"
}
}
}
},
"id": "69adfbc6-41ae-4fd8-9ac9-6619733ed6d8",
"name": "Gotenberg: Cover PDF",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
544,
1744
],
"notes": "DIN A4 statt Letter: paperWidth/paperHeight in Zoll (8.27 x 11.69) mitgeschickt. Gotenberg-Host anpassen, falls nicht im selben Docker-Netzwerk unter 'gotenberg:3000' erreichbar."
},
{
"parameters": {
"jsCode": "const inputItem = $input.first();\nconst binaryKeys = Object.keys(inputItem.binary || {})\n .filter(k => k.toLowerCase().startsWith('attachment'));\n\nif (binaryKeys.length === 0) {\n // Keine Anhänge vorhanden - dieser Zweig liefert dann einfach keine Items,\n // der Merge-Schritt weiter unten bekommt nur das Cover-PDF.\n return [];\n}\n\nreturn binaryKeys.map((key, idx) => {\n const bin = inputItem.binary[key];\n return {\n json: {\n originalIndex: idx,\n originalName: bin.fileName || `attachment_${idx}`,\n mimeType: bin.mimeType || 'application/octet-stream'\n },\n binary: {\n data: bin\n }\n };\n});"
},
"id": "883b5242-4776-4f23-aca0-c9aec9fa8bd6",
"name": "Extract Attachments",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
288,
2080
]
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 1
},
"conditions": [
{
"id": "c1",
"leftValue": "={{$json.mimeType}}",
"rightValue": "pdf",
"operator": {
"type": "string",
"operation": "contains"
}
}
],
"combinator": "and"
},
"options": {}
},
"id": "35a7f9d2-6d68-45ac-a909-895989cd5fb1",
"name": "Is Already PDF?",
"type": "n8n-nodes-base.if",
"typeVersion": 2,
"position": [
544,
2080
],
"notes": "TRUE = Anhang ist bereits PDF (geht direkt weiter). FALSE = muss per LibreOffice konvertiert werden."
},
{
"parameters": {
"method": "POST",
"url": "http://gotenberg:3000/forms/libreoffice/convert",
"sendBody": true,
"contentType": "multipart-form-data",
"bodyParameters": {
"parameters": [
{
"parameterType": "formBinaryData",
"name": "files",
"inputDataFieldName": "data"
}
]
},
"options": {
"response": {
"response": {
"responseFormat": "file"
}
}
}
},
"id": "c8799158-0d17-4063-be73-eb6b0ae1e3ed",
"name": "Gotenberg: Convert Attachment",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
800,
2192
]
},
{
"parameters": {
"jsCode": "// Nach der Gotenberg-Konvertierung (LibreOffice) gehen Original-Metadaten\n// im JSON-Teil des Items oft verloren, weil der HTTP-Request-Node den\n// Binär-Response als neues Item zurückgibt. Hier holen wir uns die\n// Metadaten über die Item-Linie aus dem Node \"Extract Attachments\" zurück.\nconst converted = $input.first();\nconst original = $('Extract Attachments').item;\n\nreturn [{\n json: {\n originalIndex: original.json.originalIndex,\n originalName: original.json.originalName,\n mimeType: 'application/pdf'\n },\n binary: {\n data: converted.binary.data\n }\n}];"
},
"id": "0f0c33fb-fb55-4d43-be16-41580c48bbb0",
"name": "Restore Metadata After Convert",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
1056,
2192
]
},
{
"parameters": {},
"id": "678aadf1-3310-4551-8a19-99da05248a75",
"name": "Combine Attachment Branches",
"type": "n8n-nodes-base.merge",
"typeVersion": 2,
"position": [
1328,
2032
]
},
{
"parameters": {
"jsCode": "// Alle konvertierten + bereits-PDF-Anhänge wieder in die ursprüngliche\n// Anhang-Reihenfolge der E-Mail sortieren.\nconst all = $input.all();\nreturn all\n .filter(i => i.json && i.json.originalIndex !== undefined)\n .sort((a, b) => a.json.originalIndex - b.json.originalIndex);"
},
"id": "3893ad38-9160-429b-8fb3-b75a5f09287b",
"name": "Sort Attachments By Original Index",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
1552,
2032
]
},
{
"parameters": {},
"id": "4e66d28f-bb9d-432f-9b78-6931f39c9daf",
"name": "Combine Cover + Attachments",
"type": "n8n-nodes-base.merge",
"typeVersion": 2,
"position": [
1840,
1904
],
"notes": "Input 1 = Cover-PDF, Input 2 = sortierte Anhänge. 'append' haengt Input2 hinter Input1 an -> Cover bleibt vorne."
},
{
"parameters": {
"jsCode": "// Dieser Node läuft im Modus \"Run Once for All Items\".\n// Input-Reihenfolge: Item 0 = Cover-PDF (Mailtext), Item 1..n = Anhänge\n// in Original-Reihenfolge. Wir bauen daraus einen multipart/form-data-\n// Request an Gotenberg /forms/pdfengines/merge.\n//\n// WICHTIG (Lessons learned, in dieser Reihenfolge ausprobiert):\n// 1. Binärdaten IMMER über getBinaryDataBuffer() lesen, NICHT über\n// item.binary.data.data direkt.\n// 2. this.helpers.httpRequest() (axios) und globales fetch() haben sich\n// beide als unzuverlässig herausgestellt beim Senden von\n// multipart/form-data mit mehreren dynamischen Dateien (415 / \"no\n// form file found\"). fetch() war zudem im Sandbox gar nicht\n// verfügbar.\n// 3. Deshalb hier: rohes Node-Core-Modul 'http' nutzen - keine\n// automatische Content-Type-Erkennung, kein \"Mitdenken\" einer\n// Bibliothek, volle Kontrolle über die Bytes auf der Leitung.\n//\n// VORAUSSETZUNG: Umgebungsvariable NODE_FUNCTION_ALLOW_BUILTIN muss\n// 'http' enthalten (z.B. NODE_FUNCTION_ALLOW_BUILTIN=http oder\n// NODE_FUNCTION_ALLOW_BUILTIN=buffer,http), sonst \"Module 'http' is\n// disallowed\".\n\nconst http = require('http');\n\nconst items = $input.all();\n\nfunction safeBaseName(name) {\n return String(name || 'datei').replace(/\\.[^/.]+$/, '').replace(/[^a-zA-Z0-9_\\-]/g, '_');\n}\n\nfunction buildMultipart(parts) {\n const boundary = '----n8nGotenberg' + Date.now();\n const chunks = [];\n for (const part of parts) {\n chunks.push(Buffer.from(`--${boundary}\\r\\n`));\n chunks.push(Buffer.from(`Content-Disposition: form-data; name=\"files\"; filename=\"${part.filename}\"\\r\\n`));\n chunks.push(Buffer.from(`Content-Type: ${part.contentType}\\r\\n\\r\\n`));\n chunks.push(part.data);\n chunks.push(Buffer.from('\\r\\n'));\n }\n chunks.push(Buffer.from(`--${boundary}--\\r\\n`));\n return { body: Buffer.concat(chunks), boundary };\n}\n\nfunction postMultipart(host, port, path, body, boundary) {\n return new Promise((resolve, reject) => {\n const req = http.request(\n {\n host,\n port,\n path,\n method: 'POST',\n headers: {\n 'Content-Type': `multipart/form-data; boundary=${boundary}`,\n 'Content-Length': body.length\n }\n },\n (res) => {\n const responseChunks = [];\n res.on('data', (c) => responseChunks.push(c));\n res.on('end', () => {\n const responseBuffer = Buffer.concat(responseChunks);\n if (res.statusCode < 200 || res.statusCode >= 300) {\n reject(new Error(`HTTP ${res.statusCode}: ${responseBuffer.toString('utf-8')}`));\n } else {\n resolve(responseBuffer);\n }\n });\n }\n );\n req.on('error', reject);\n req.write(body);\n req.end();\n });\n}\n\nconst parts = [];\nfor (let idx = 0; idx < items.length; idx++) {\n const item = items[idx];\n const buffer = await this.helpers.getBinaryDataBuffer(idx, 'data');\n\n if (!buffer || buffer.length === 0) {\n throw new Error(`Leeres Binary bei Item ${idx} (originalName: ${item.json.originalName || 'Cover'}) - Datei wurde nicht korrekt durchgereicht.`);\n }\n\n const filename = idx === 0\n ? '0_mailtext.pdf'\n : `${idx}_${safeBaseName(item.json.originalName)}.pdf`;\n\n parts.push({ filename, contentType: 'application/pdf', data: buffer });\n}\n\nconst { body, boundary } = buildMultipart(parts);\n\nlet mergedBuffer;\ntry {\n // Host/Port ggf. anpassen, falls Gotenberg nicht unter 'gotenberg:3000' im Docker-Netz läuft\n mergedBuffer = await postMultipart('gotenberg', 3000, '/forms/pdfengines/merge', body, boundary);\n} catch (error) {\n throw new Error(`Gotenberg-Merge fehlgeschlagen: ${error.message}`);\n}\n\nreturn [{\n json: {\n mergedFileCount: items.length,\n subject: $('Build Cover HTML').first().json.subject,\n mailDate: $('Build Cover HTML').first().json.mailDate\n },\n binary: {\n data: {\n data: mergedBuffer.toString('base64'),\n fileName: 'merged.pdf',\n mimeType: 'application/pdf'\n }\n }\n}];"
},
"id": "a8102d6d-108d-4257-aba2-4f42c22d9343",
"name": "Merge PDFs via Gotenberg",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
2096,
1904
],
"notes": "Nutzt jetzt rohes Node-Core-Modul 'http' statt this.helpers.httpRequest() oder fetch() - umgeht damit jegliche automatische Content-Type-Verarbeitung von Wrapper-Bibliotheken, die zu 415/'no form file found' fuehrte. NODE_FUNCTION_ALLOW_BUILTIN muss 'http' enthalten (z.B. NODE_FUNCTION_ALLOW_BUILTIN=buffer,http)."
},
{
"parameters": {
"method": "POST",
"url": "https://dms.korte-kernke.koeln/api/documents/post_document/",
"authentication": "genericCredentialType",
"genericAuthType": "httpHeaderAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Authorization",
"value": "Token b3361c0fd58889ee6fe3ec3ee9a0c2f3bea3f818"
}
]
},
"sendBody": true,
"contentType": "multipart-form-data",
"bodyParameters": {
"parameters": [
{
"parameterType": "formBinaryData",
"name": "document",
"inputDataFieldName": "data"
},
{
"name": "title",
"value": "={{ $('Build Cover HTML').first().json.subject }}"
},
{
"name": "created",
"value": "={{ $('Build Cover HTML').first().json.mailDate }}"
}
]
},
"options": {
"response": {
"response": {
"responseFormat": "text"
}
}
}
},
"id": "2a19e976-9a51-47ec-abf6-f33bd095a0ed",
"name": "Paperless: Upload Document",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
2368,
1904
],
"credentials": {
"httpHeaderAuth": {
"id": "YzufsPqSvVy9qIIe",
"name": "Header Auth account"
}
},
"notes": "Response Format auf 'Text' gestellt, da post_document nur die Task-UUID als Plain-Text (kein valides JSON) zurueckgibt. URL und Token anpassen! Besser: eigene n8n-Credential vom Typ 'Header Auth' statt Token im Klartext."
}
],
"connections": {
"Email Trigger (IMAP)": {
"main": [
[
{
"node": "Build Cover HTML",
"type": "main",
"index": 0
},
{
"node": "Extract Attachments",
"type": "main",
"index": 0
}
]
]
},
"Build Cover HTML": {
"main": [
[
{
"node": "Gotenberg: Cover PDF",
"type": "main",
"index": 0
}
]
]
},
"Gotenberg: Cover PDF": {
"main": [
[
{
"node": "Combine Cover + Attachments",
"type": "main",
"index": 0
}
]
]
},
"Extract Attachments": {
"main": [
[
{
"node": "Is Already PDF?",
"type": "main",
"index": 0
}
]
]
},
"Is Already PDF?": {
"main": [
[
{
"node": "Combine Attachment Branches",
"type": "main",
"index": 0
}
],
[
{
"node": "Gotenberg: Convert Attachment",
"type": "main",
"index": 0
}
]
]
},
"Gotenberg: Convert Attachment": {
"main": [
[
{
"node": "Restore Metadata After Convert",
"type": "main",
"index": 0
}
]
]
},
"Restore Metadata After Convert": {
"main": [
[
{
"node": "Combine Attachment Branches",
"type": "main",
"index": 1
}
]
]
},
"Combine Attachment Branches": {
"main": [
[
{
"node": "Sort Attachments By Original Index",
"type": "main",
"index": 0
}
]
]
},
"Sort Attachments By Original Index": {
"main": [
[
{
"node": "Combine Cover + Attachments",
"type": "main",
"index": 1
}
]
]
},
"Combine Cover + Attachments": {
"main": [
[
{
"node": "Merge PDFs via Gotenberg",
"type": "main",
"index": 0
}
]
]
},
"Merge PDFs via Gotenberg": {
"main": [
[
{
"node": "Paperless: Upload Document",
"type": "main",
"index": 0
}
]
]
},
"Paperless: Upload Document": {
"main": [
[
{
"node": "IMAP: Move to archiviert",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "df6b67e4a3409a1bb65dc9d259dadbe775966bb0ced00827d2056f673f305938"
}
}